A publication by datasciencepartners.nl about Roseman Labs package, crandas.
With Roseman Labs, (sensitive) data from different parties can be combined in a secure way. After which, the merged data can be reviewed and analyzed, without any party having access to the data of another party. This offers a solution when sensitive data should be merged to obtain valuable insights, but because of its sensitivity this is not possible nor desired.
1. Why share data? An example in healthcare
Bringing together data from different parties can lead to new valuable insights. To understand this, let's look at an example in healthcare. This involves the situation of multiple hospitals all treating patients with a particular condition:
- Each of the hospitals only has the data from its own patients, and has no access to the data from other hospitals.
- In this example, the data that each hospital has separately is too limited to draw conclusions about whether a particular treatment is effective.
- When the data from the different hospitals are brought together, this dataset is statistically stronger.
- This may allow conclusions to be drawn from the combined dataset about the effect of a particular treatment.
- This can help improve care.
The above example is only one of many possible applications of combining data. In this example, we combined similar data of different patients from multiple hospitals. You can also aggregate data of the same patient from different sources. For example, merging patient data from a general practitioner with that of a hospital. These types of examples are not just limited to healthcare, and are just as possible within other sectors such as the public sector, energy sector, or financial services.
2. Challenges in sharing data
When data contains personal information, the General Data Protection Regulation (GDPR) legislation applies. This legislation establishes strict guidelines regarding the sharing of personal data. According to GDPR, personal data may only be shared if there is a lawful basis. For example, with explicit consent of the data subjects. In addition, GDPR requires parties sharing personal data to take appropriate technical and organizational measures to ensure a high level of data protection. As a result, data containing personal information may therefore not simply be shared between parties.
Besides the fact that GDPR may be applicable, a party may not want to share data with another party 'just like that'. Perhaps because the data contains company-sensitive information.
So there are several reasons why sharing data with another party may not be desired or possible. But that there is added value of bringing together and analyzing data from different parties.
3. Solving data sharing challenges: Roseman Labs
Roseman Labs offers a solution with their software and a proprietary package for Python programming language: crandas. Such a technical solution to improve and/or ensure privacy is also called a privacy enhancing technology (PET).
Roseman Labs makes it possible to securely merge sensitive data from different parties to unlock valuable insights, all without storing a centralized dataset anywhere.
And without anyone from one party being able to see other participants' data.
To do this, Roseman Labs uses a technique called secure Multi-Party Computation, which works as follows:
- Each of the parties encrypts their data locally. As part of this, the data is split into pieces.
- This encrypted and split data is uploaded to different servers.
- Through the python package crandas, the data can be virtually combined and analyzed, without the need to decrypt the original data.
To experience this in practice, we will go through an example in the following steps.
4. Example using Roseman Labs software and python package, crandas
In this example, we are working with 3 datasets containing diabetic patient data from different hospitals. These datasets have been added to Roseman Labs by each of the hospitals. This allows you as a data analyst or researcher, if you have appropriate permissions, to analyze and examine the 3 datasets from the 3 hospitals, but not to view them. Thus, this method can be used as a secure way to exchange data.
4.1. Uploading datasets
In this example, we are using a demo environment of Roseman Labs. And within this, we are working in a Jupyter Labs environment with Python programming language. In a production environment of Roseman Labs, you can only work with scripts approved by data holders/controllers.
In this demo environment there are already the 3 datasets with data of diabetes patients from different hospitals. First, we are going to read and upload the datasets. By doing so, we simulate the situation that each of the hospitals would have uploaded a dataset to Roseman Labs.
To work with datasets from Roseman Labs, we use their package crandas. This is partly based on pandas, the most commonly used package to work with tabular data.
4.1.1. Upload
In the code below we do the following:
- Import the python package crandas.
- Specify the file paths of the datasets.
- Read out the 3 datasets using the read_csv() method. This is very similar to how you would read a CSV file with pandas.
- Through the read, the datasets are uploaded to Roseman Labs..
- Store the 3 datasets in variables df_1, df_2 and df_3.

4.1.2. Handles
Each dataset uploaded to Roseman Labs has a handle. This is a reference to the dataset that consists of a 64-character hexadecimal string. We obtain these handles in this example as follows:
- Obtain the handles with attribute handle, for each dataset.
- Store these handles in variables.
- Display one handle, as an example.

We have now simulated a real-world situation. This where each of the 3 hospitals would have uploaded a dataset to Roseman Labs, and where we have a known handle of each dataset in the Roseman Labs platform. This acts as a reference to the dataset, which we need to use to analyze the dataset in Roseman Labs.
4.2. Accessing datasets
Roseman Labs is designed to protect datasets. Therefore, you cannot just read a dataset as you would read a CSV file with pandas, for example. Instead, Roseman Labs allows you to access a dataset from crandas with function get_table(). You can then use the dataset, but have very limited access to the underlying data.
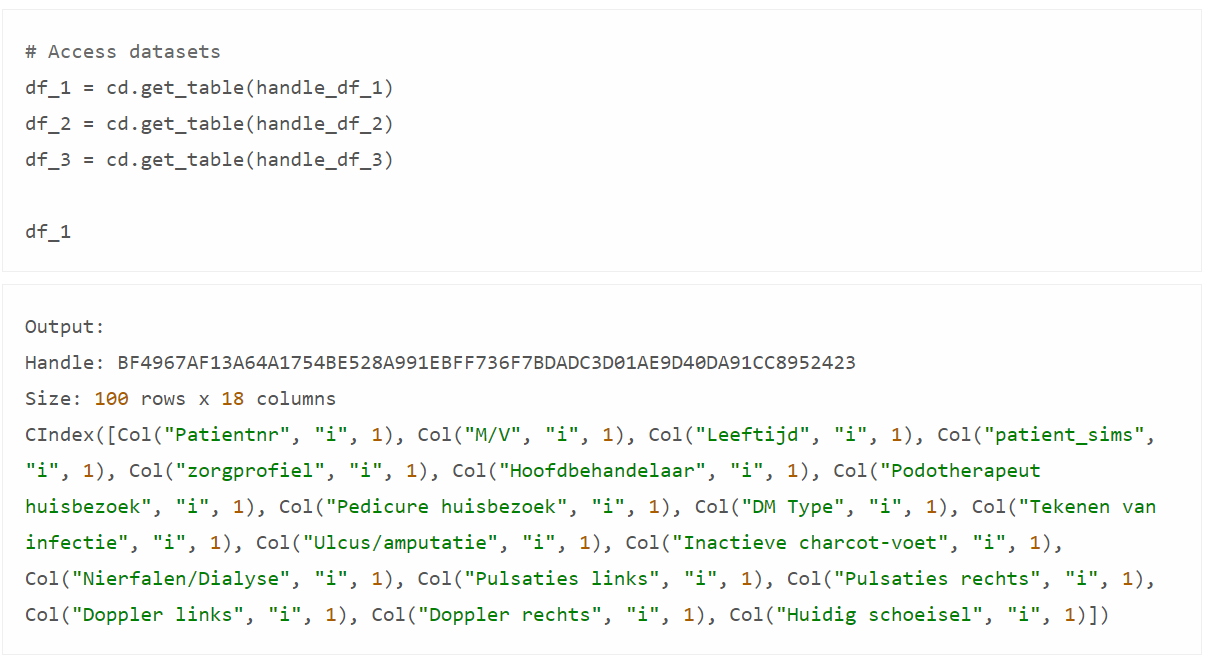
In the code below we read out the 3 datasets using the by now familiar handles. We can view the output of one dataset.

We now see some details of the dataset: the handle, the shape, and information about the columns. But not the actual data; that is protected.
In the code below, we give each dataset a name, with attribute name. We'll use this later in this example.

It can be seen that the datasets have been named.
4.3. Exploring datasets
With pandas , there are several ways to explore datasets. Some of these can also be used with crandas. However, crandas has not implemented methods by which a dataset can be fully or partially seen. This is for shielding, thus maintaining the security of the data.
4.3.1. Exploring cell values
For example, the head() method that we are familiar with in pandas is not available in crandas. This is because this method shows you the cells of the first 5 rows. Crandas provides data masking. Therefore, we cannot use this method. See the example below.

We get an AttributeError because method head() does not exist. The same applies when using iloc[]. This is a method that allows us to select values from rows and columns in pandas. See the example below.

Again, we get back an AttributeError as a result.
4.3.2. Exploring column names
We can, however, use the attribute columns, for example. This gives us an overview of all column names in a dataset. Just like how it works in pandas. See the example below.

4.3.3. Number of rows and columns of datasets
With attribute shape we obtain the number of rows and columns of a data set. This works the same as in. See the example below. In it we use a for-loop to print the name and shape of the 3 datasets.
With attribute shape we obtain the number of rows and columns of a dataset. This works the same as in pandas. See the example below.
In it we use a for-loop to print the name and shape of the 3 datasets.

Each dataset consists of 100 rows and 18 columns.
4.3.4. Statistical summary of dataset
The method describe() can also be used in crandas. Just like how it works in pandas, it gives you a statistical summary of the columns. See the example below.

4.4. Adding columns
With method assign() we can add a column in crandas, just like how it works in pandas.
See the example below. Here, for example, source=df_1.name means that a new column named "source" is created, which gets the value of the name of the dataframe we are referring to. With this, each of the 3 datasets contains a column "source", with the values being the name of the dataset. See the example below.
By looking at the list of column names, we check whether the new column "source" has been added. See the example below.

We can see that the column named "source" is now present.
In this example, we simply added a column containing the name of a dataset. For example, we could also have added a column with values based on a calculation.
4.5. Merging datasets
Despite not being able to see datasets directly, crandas does allow us to merge datasets. Thereby there are similar possibilities as in pandas. This is possible with methods merge() and concat().
In this example, the 3 datasets have the same column structure. We are going to merge the rows of the 3 datasets into 1 combined dataset. For this we use the concat() method. See the example below.
We store the combined dataset in the variable named df_combined.
Here we combine 3 times 100 rows, from 19 columns. The combined dataset should then contain 300 rows and 19 columns. We check this with the shape attribute.

We see that the combined dataset has the shape we expected.
4.6. Analyzing datasets
Crandas offers all kinds of possibilities to analyze data and to perform statistical tests. For example, linear regression and logistisic regression are possible.
4.6.1. Selection and calculation
Crandas screens the data from the datasets. However, it does allow us to filter to make specific selections. It also allows us to perform calculations on numeric columns. For example, using the mean() method. With this, you calculate the average of values in a column.
In the example below, we do the following:
- In the combined dataset, we make specific selections based on column
"source". - For each selection, we calculate the average age from column
"age"with the mean() method. - We print the results.

We now see the average age for each selection.
4.6.2. Visualizing
We can visualize the calculated result, for example with a graph using matplotlib. Learn more about matplotlib here.
In the example below, we create a bar graph containing the calculated average ages.

Output: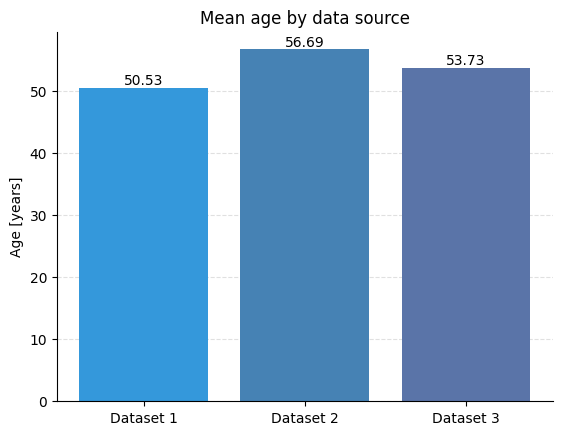
We can now see a nice visualization of the analyzed data.
4.7. Conclusion: use crandas
With Roseman Labs and the crandas python package, we were able to do the following:
- Read datasets
- Link datasets
- Analyze datasets
And we did this without directly accessing data from each of the datasets. This kept the data safely shielded, but allowed us to gain valuable insights from the data.
5. Conclusion
Roseman Labs is a solution for gaining valuable insights from data from multiple parties, without having to actually combine that data at any of the parties. This makes it a great technology for situations where data sharing is not possible or allowed, but insights from combined data are desired. To work with the Roseman Labs platform, you need to use their package crandas for the Python programming language. Because this package is partly based on package pandas, it works very easily and intuitively for a data analyst familiar with Python.
You can read the original article here.